Title: Differentiate-and-Inject Enhancing VLAs via Functional Differentiation Induced by In-Parameter Structural Reasoning
Authors: Jingyi Hou, Leyu Zhou, Chenchen Jing, Jinghan Yang, Xinbo Yu, Wei He
arXiv: https://arxiv.org/abs/2602.07541
论文关注 VLA 在复杂任务中“看起来全能、实际耦合混乱”的问题。核心思想是先通过结构化推理把任务拆成功能角色,再把这些角色作为可注入的参数化偏置写回模型,从而减少视觉理解、任务推理、动作解码之间的互相污染。它不是再加一个大模块,而是试图改造参数空间里的功能分工。
从建模角度看,这类方法都在回答一个共同问题:如何把高维感知映射为对控制真正有用的中间变量。文中通常可以写成“目标 + 约束”的联合优化形式:
其中 对应任务成功与效率, 对应论文强调的结构先验(意图对齐、历史条件、协商一致性或可规划性)。阅读时不要只看公式形式是否新,更要看结构项到底改变了哪些训练样本、哪些决策边界、以及哪些失败模式。
实验部分建议按“三层问题”去读。第一层看终点指标是否提升,第二层看学习曲线前半段斜率是否更陡,因为这决定了真实系统试错成本,第三层看消融是否证明关键机制不可替代。很多论文最终分数差距并不夸张,但若在早期样本效率、长尾失败率和跨场景稳定性上有系统性改进,实际价值往往更高。
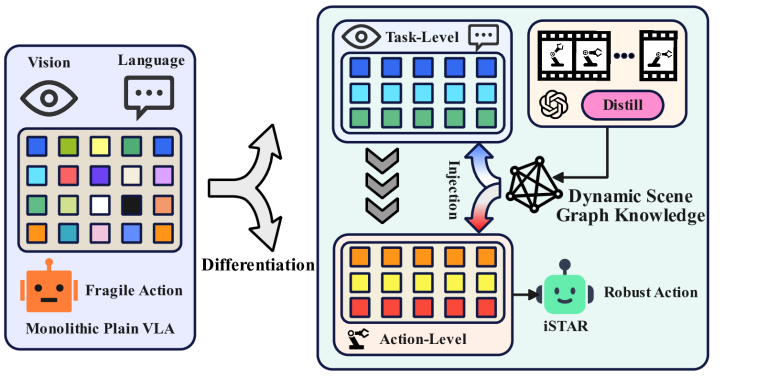

局限性方面,这批工作普遍面临两个共性挑战。其一是分布外泛化:当感知噪声、接触动力学或多人交互模式突然变化时,中间表示是否仍然保真。其二是工程闭环:离线指标与在线部署收益常常不一致,尤其在延迟、执行器饱和、通信抖动存在时。你后续复现时可以优先记录“到达阈值性能所需真实时间”与“失败样本类型转移”,这比单个平均成功率更能反映方法强弱。
如果把这篇放到今日研究主线里,它最有启发的地方是:把抽象层设计(意图、协商、规划、完成态、身体关键部位)直接和可执行控制收益绑定,而不是停留在语义解释层。下一步可考虑把不确定性估计并入该结构项,例如用
对高不确定状态进行重加权采样,让系统自动把预算分配到最值得学习的区域。这样你得到的不只是一篇论文结论,而是一套可迁移到 VLA、灵巧手与人形任务的研究方法论。
进一步把论文读深一层,我建议你把实验章节当作“因果验证”而不是“排行榜展示”。先锁定作者宣称的关键机制,再逐个对照实验看它到底改变了什么。如果机制声称改善了时序决策,那么你应该在时序误差、任务阶段切换点、失败恢复速度上看到一致变化;如果机制声称改善了跨场景泛化,那么你应该在摄像机位姿、物体几何、摩擦条件、干扰主体数量变化后依然看到优势存在。很多论文会在主表上给平均分,但真正能支持结论的是分场景分难度的细粒度统计,这部分通常埋在附录或补充材料里,值得优先读。
从可复现实验设计看,可以采用“固定预算、固定硬件、固定数据入口”的三固定原则,避免把工程差异误判成算法增益。训练目标可写成
其中 KL 项代表更新稳定性约束。对真实机器人任务,除了 success rate,我建议至少同步记录每回合平均时长、动作饱和比例、恢复动作占比、以及失败类型分布。这样你可以判断模型到底是“更聪明了”,还是只是“更保守了”。如果一个方法成功率上升但回合时长显著拉长,或者恢复动作激增,那么它的部署收益可能被高估。
最后是未来方向。今天这批论文的共同机会点,是把结构化中间变量和不确定性估计统一起来,让系统在推理、规划、控制三层共享同一套风险感知。一个可落地方向是引入校准后的置信度头,对关键中间状态做温度缩放或 conformal 约束,再把风险信号反馈给采样器与规划器,形成“高风险先学习、低风险快执行”的双通道闭环。若这个方向成立,你后续在 VLA、灵巧手、人形与多机器人系统上可以复用同一评测框架,从而真正积累跨论文、跨任务可迁移的研究资产。