Title: Rethinking Visual-Language-Action Model Scaling Alignment, Mixture, and Regularization
Authors: Ye Wang, Sipeng Zheng, Hao Luo, Wanpeng Zhang, Haoqi Yuan, Chaoyi Xu, Haiweng Xu, Yicheng Feng, Mingyang Yu, Zhiyu Kang, Zongqing Lu, Qin Jin
arXiv: https://arxiv.org/abs/2602.09722
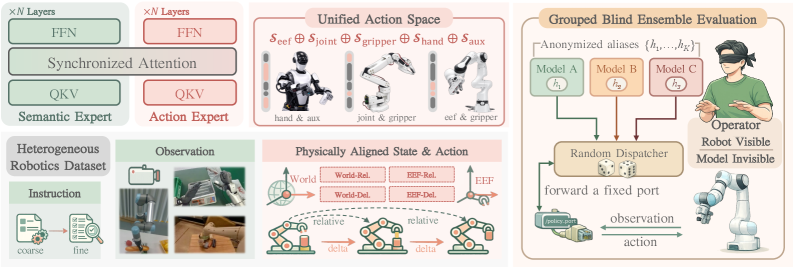
这篇论文最重要的结论是:VLA 的扩展规律并不等价于“数据越多越好”。当不同本体、传感器和动作定义被生硬混合时,负迁移会迅速吞掉规模红利。作者把问题拆成三个可控变量:动作对齐、数据混合、正则化,并通过分组盲评协议尽量降低评估偏差。
其中动作统一可写成 ,混合训练则是
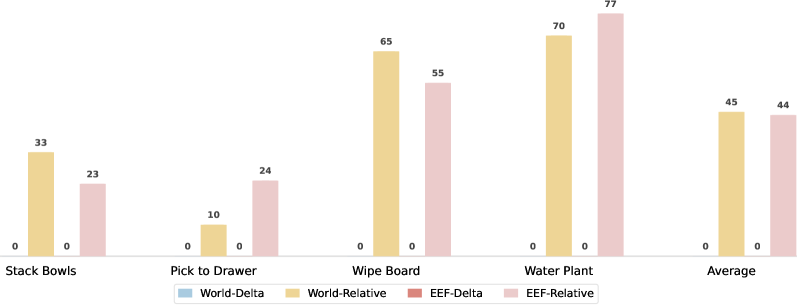
论文价值在于给出“何时会负迁移”的可操作证据,而不是停留在经验判断。读实验时建议盯住等算力条件下的对齐/未对齐对比、混合比例拐点、以及不同正则在跨任务上的收益分化。可落地方向是做在线 mixture reweighting,让数据配比由迁移信号动态驱动。
Figures