Title: VLA-JEPA Enhancing Vision-Language-Action Model with Latent World Model
Authors: Jingwen Sun, Wenyao Zhang, Zekun Qi, Shaojie Ren, Zezhi Liu, Hanxin Zhu, Guangzhong Sun, Xin Jin, Zhibo Chen
arXiv: https://arxiv.org/abs/2602.10098
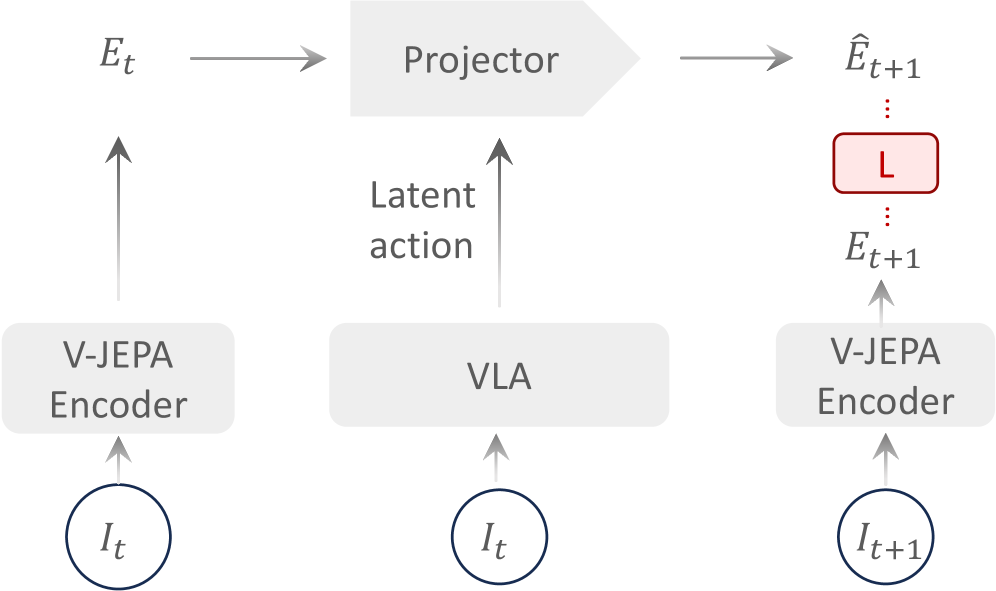
VLA-JEPA的主张很清晰:机器人预训练不应被像素重建牵着走,因为像素损失会过度奖励纹理细节并可能引入“偷看未来”的捷径。作者改用 JEPA 风格潜变量预测,把学习目标压到 action-relevant 的动态结构上,再把该表征用于下游策略学习。
定义目标潜变量与预测潜变量为 、,损失为
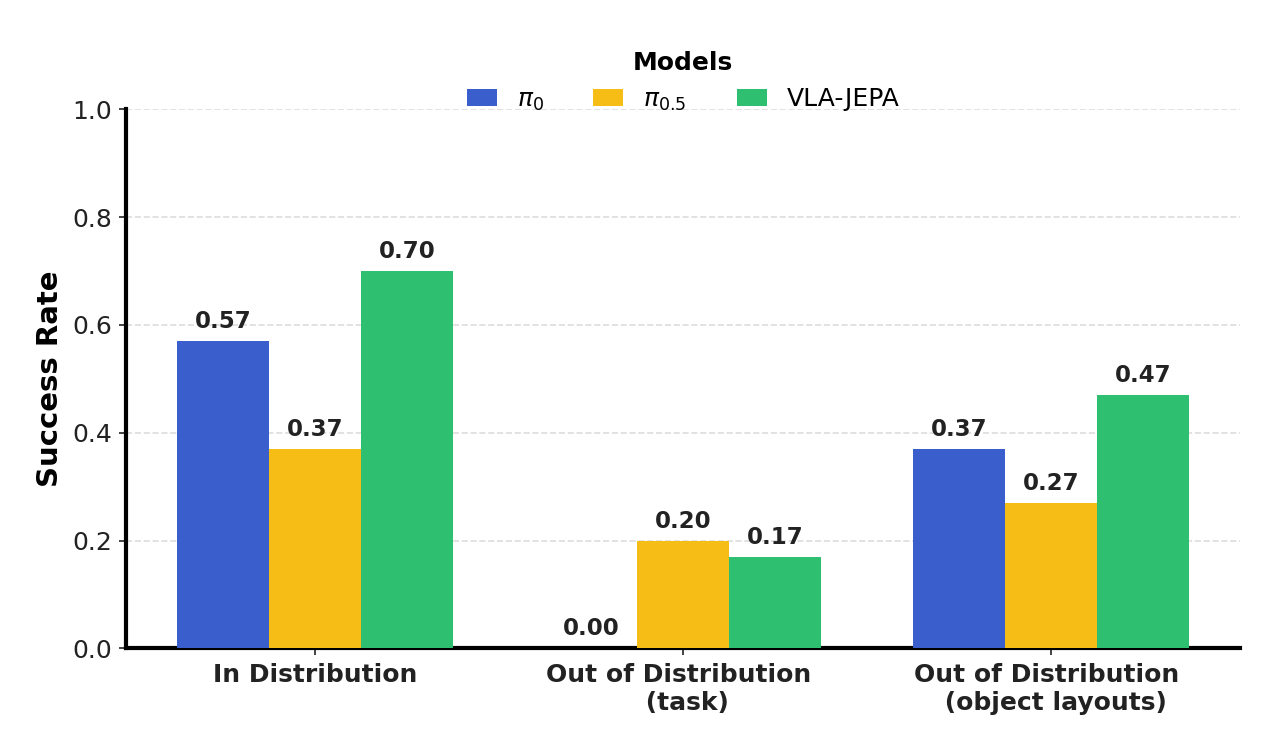
该路线的优点是目标更贴近控制需求,且常对背景扰动更稳。读实验建议重点看:在相机位姿/背景变化下的性能退化斜率,以及下游微调样本效率是否改善。局限在于潜空间压缩过强可能损失细粒度接触信息,预测 horizon 也存在误差累积权衡。
Figures