Title: ST4VLA Spatially Guided Training for Vision-Language-Action Models
Authors: Jinhui Ye, Fangjing Wang, Ning Gao, Junqiu Yu, Yangkun Zhu, Bin Wang, Jinyu Zhang, Weiyang Jin, Yanwei Fu, Feng Zheng, Yilun Chen, Jiangmiao Pang
arXiv: https://arxiv.org/abs/2602.10109
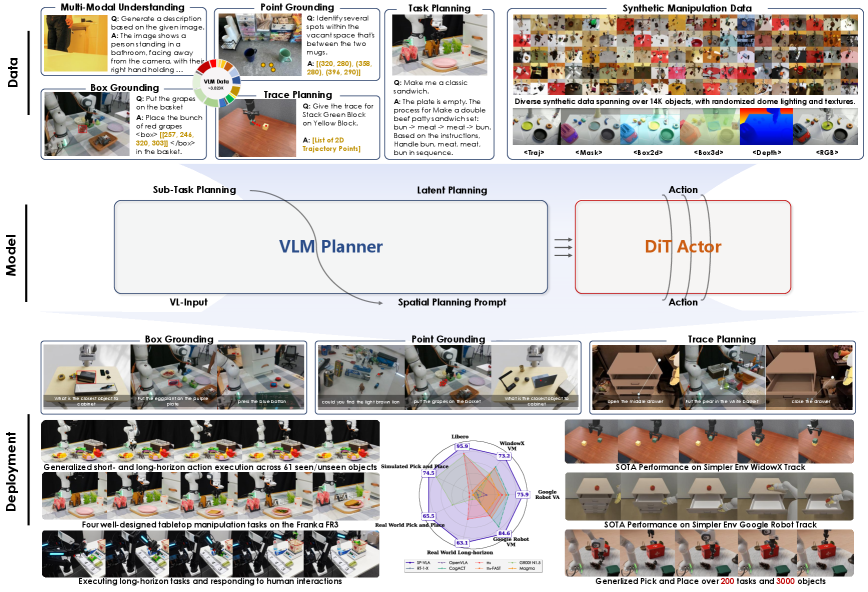
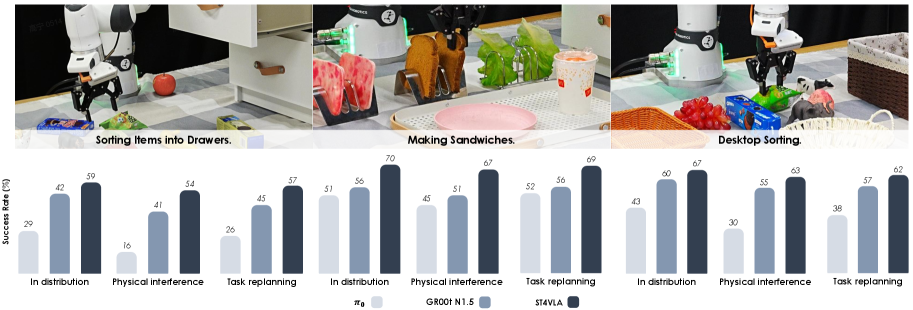
ST4VLA瞄准的是 VLA 中常见的“语义懂了、空间丢了”问题。很多模型在动作监督下会牺牲几何 grounding,导致指令执行时定位和轨迹偏差累积。作者采用两阶段训练:先做空间引导预训练,再做带空间约束的动作后训练,让几何信号贯穿整个学习过程。
统一损失写成
其中 的平衡决定空间信息能否在动作梯度下存活。看实验时建议分三层:基础任务成功率、未见物体与语言改写鲁棒性、长时程干扰下误差累积。核心判断标准不是短程命中率,而是 rollout 后段是否仍保留稳定的空间对齐能力。
Figures