Title: RISE Self-Improving Robot Policy with Compositional World Model
Authors: Jiazhi Yang, Kunyang Lin, Jinwei Li, Wencong Zhang, Tianwei Lin, Longyan Wu, Zhizhong Su, Hao Zhao, Ya-Qin Zhang, Li Chen, Ping Luo, Xiangyu Yue, Hongyang Li
arXiv: https://arxiv.org/abs/2602.11075
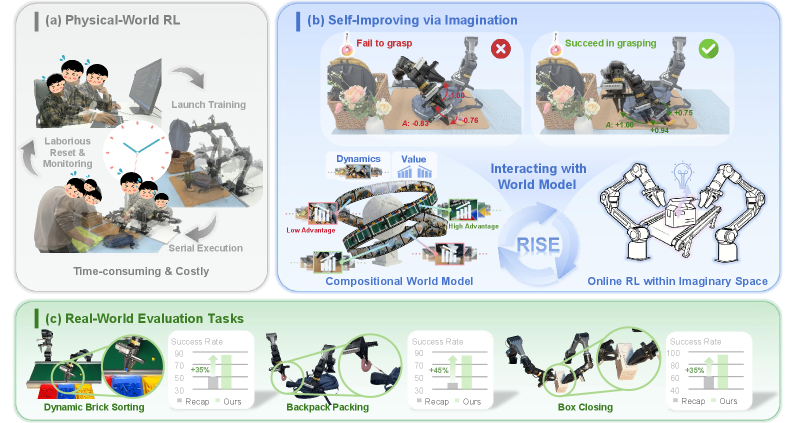
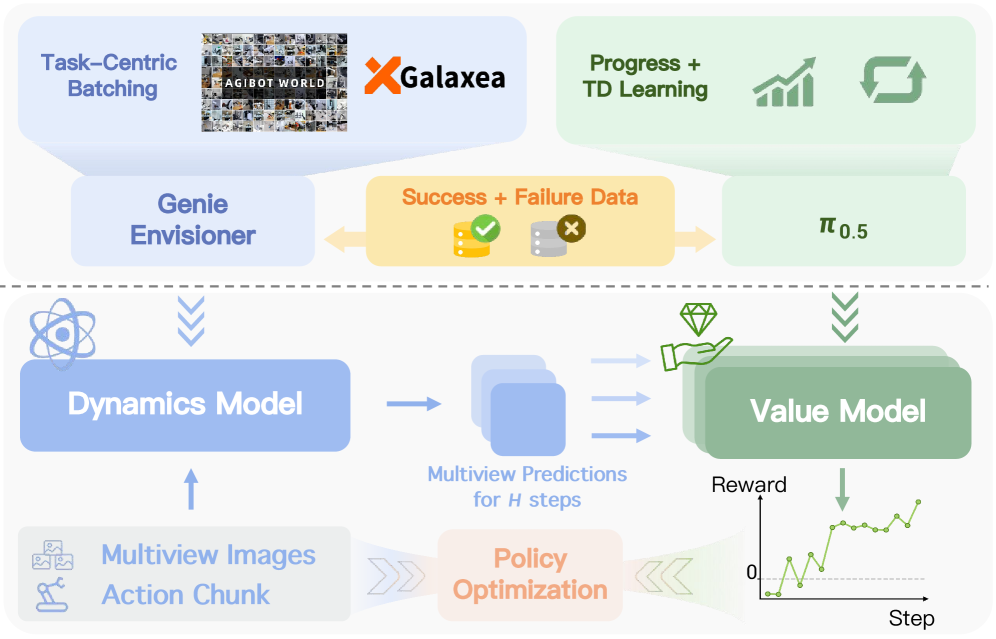
RISE的出发点很实际:接触密集任务里,纯 VLA 往往对执行偏差高度脆弱,而真机在线 RL 的试错成本又太高。作者给出的解法是“组合世界模型 + 进度价值模型”,把大部分策略改进迁移到 imagination 空间中完成,只保留必要的真机刷新。
想象轨迹由 采样,再由进度价值 评估;优势可写为
并用 更新策略。组合式建模把动力学预测和任务进度评估拆开,有利于在复杂任务里控制误差传播。阅读时重点看“性能-真机交互预算”曲线与失败恢复质量。风险依旧在世界模型偏差,尤其长 horizon 想象时误差会累积。
Figures