Title: Data-Efficient Hierarchical Goal-Conditioned Reinforcement Learning via Normalizing Flows
Authors: Shaswat Garg, Matin Moezzi, Brandon Da Silva
arXiv: https://arxiv.org/abs/2602.11142
NF-HIQL把一个常被忽视的瓶颈说透了:层级 GCRL 虽然适合长时程控制,但若高层子目标和低层动作都用单峰高斯,表达力会直接限制样本效率。作者在 HIQL 框架中把 manager/worker 都替换成 normalizing flow,以可计算似然换取多模态建模能力。
层级策略可写为 ,并延续 IQL 的隐式策略提取思想:
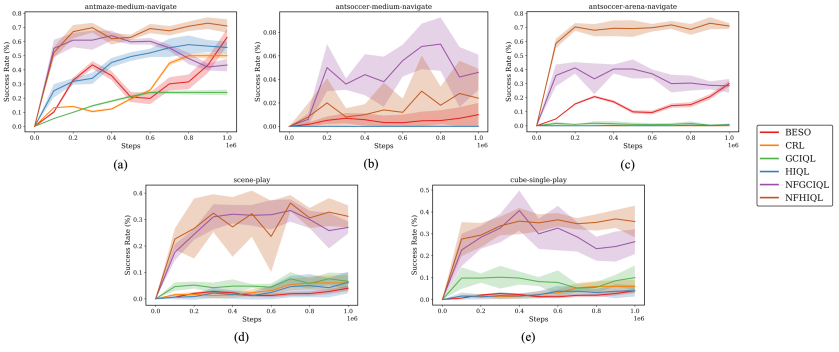
其中对数概率由 flow 雅可比项精确给出。这个改动的意义在于:不改大框架,只换策略族,就能在低数据区间更好拟合多峰子目标与动作分布。阅读建议先看低样本阶段曲线,再看多模态诊断和跨任务稳定性。
Figures