Title: Selective Perception for Robot: Task-Aware Attention in Multimodal VLA
Authors: Young-Chae Son, Jung-Woo Lee, Yoon-Ji Choi, Dae-Kwan Ko, Soo-Chul Lim
arXiv: https://arxiv.org/abs/2602.15543
Problem framing
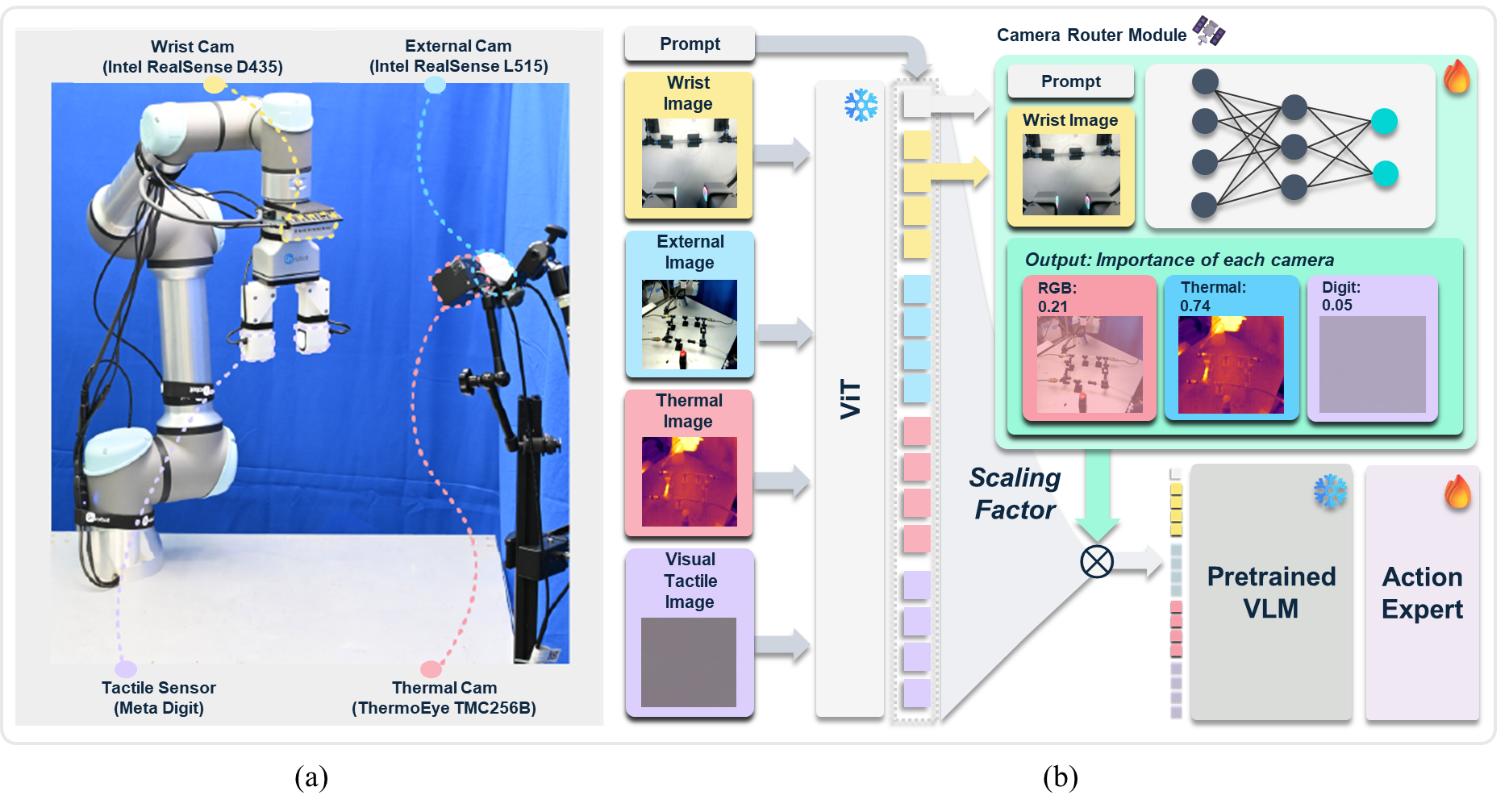
多视角 VLA 常用静态融合:每一帧、每个视角都进同样算子,导致两类问题——算力浪费与背景噪声注入。该文关注“任务相关性感知”:让模型按任务动态挑选最有信息的观察通道。
Core method
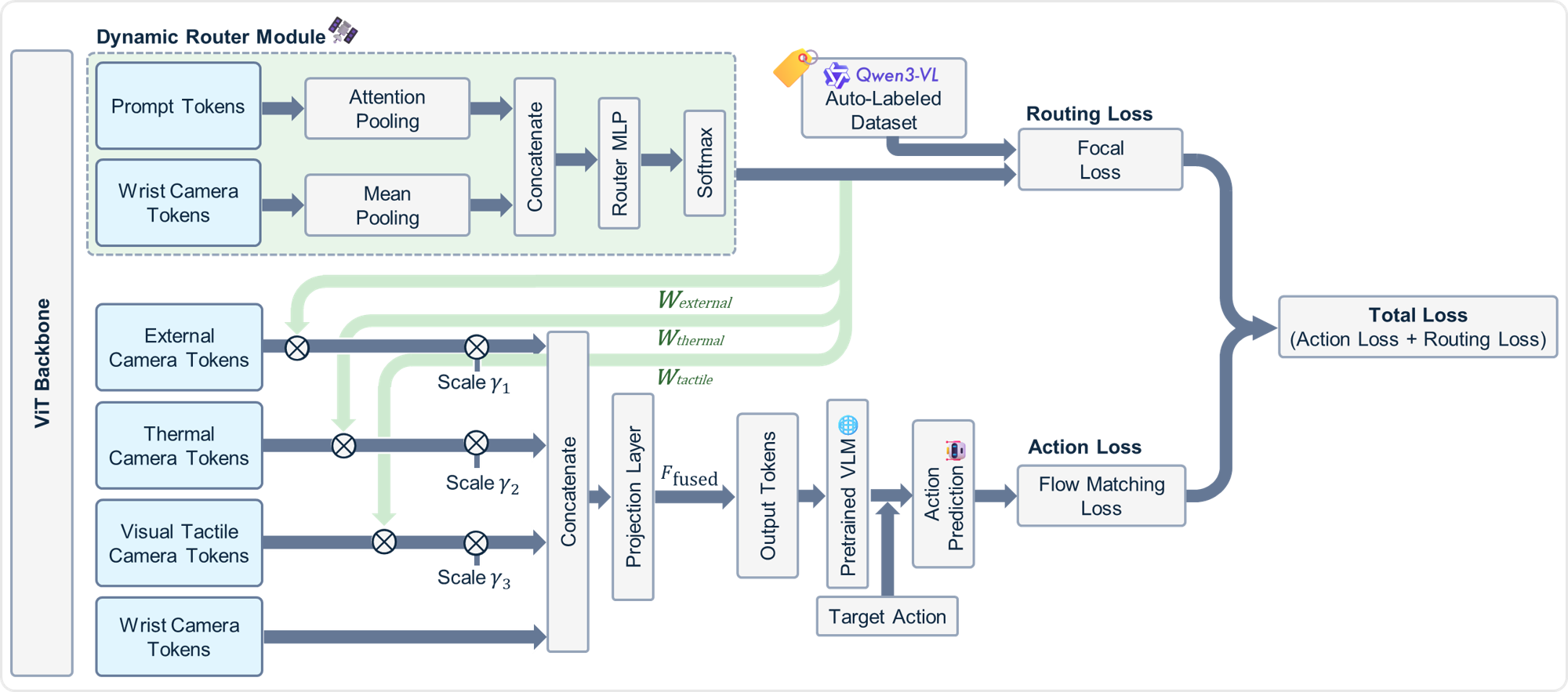
提出轻量自适应路由模块,对多模态输入做 task-aware gating:
- 先用语言指令与当前状态生成注意分配;
- 再仅对高价值视角/模态做高开销融合,低价值通道走轻路径。
可抽象为:
其中 随任务变化,达到“按需感知”。
Experiment reading guide
建议重点读:
- 计算量-性能曲线(FLOPs 降幅 vs 成功率);
- 干扰背景或遮挡条件下鲁棒性提升;
- 多任务场景中 attention 分配是否符合人类直觉。
Limitations
- 动态路由在极端实时约束下仍有调度开销;
- 若任务描述模糊,attention 可能抖动;
- 对跨机器人本体泛化还缺更系统评测。
Future work
可引入 uncertainty-aware gating(置信度驱动路由)与 memory-based token 复用,进一步降低时延并增强长时程稳定性。
Replication angle
先复现静态融合 baseline,再逐步加入 task-aware 路由与稀疏化约束,观察不同任务簇的收益差异。
Figure links
{kind=link}
{kind=link}
Graph: Paper Node 2602.15543