Title: SIT-LMPC: Safe Information-Theoretic Learning Model Predictive Control for Iterative Tasks
Authors: Zirui Zang, Ahmad Amine, Nick-Marios T. Kokolakis, Truong X. Nghiem, Ugo Rosolia, Rahul Mangharam
arXiv: https://arxiv.org/abs/2602.16187
Problem framing
迭代任务(重复赛道、重复巡检)里,控制器既要越跑越快,又不能破坏硬约束。传统 LMPC 常受限于不确定性表达能力,安全与性能会互相拉扯。
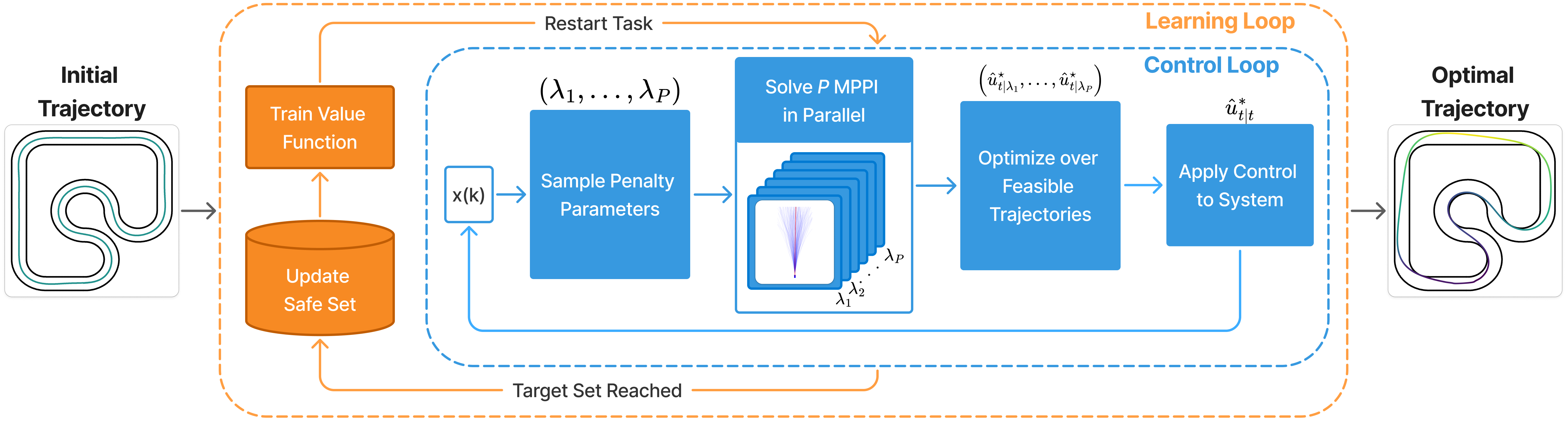
Core method
SIT-LMPC 把信息论 MPC 与学习型价值函数结合:利用历史迭代轨迹学习 value,并用 normalizing flow 建模不确定性分布,替代过于刚性的高斯先验;再引入自适应惩罚保证约束满足。
Key equations and mechanisms
可理解为求解带安全项的随机最优控制:
其中 是安全屏障/违约惩罚, 迭代自适应更新;value 学习用 flow 后验 改善尾部风险刻画。
Experiment reading guide
先看 benchmark 仿真里的迭代收敛曲线(lap time vs iteration),再看硬件实验是否在性能提升同时保持零约束违背;这是评估“安全-性能共进化”是否成立的关键。
Limitations
方法工程复杂度高,对 GPU 并行资源有要求;在低算力边端部署时可能需要蒸馏/近似。
Future work
值得关注与 world model 结合的离线 warm-start,以及把 flow 不确定性进一步用于 risk-sensitive exploration。
Replication angle
建议先复现纯信息论 MPC 基线,再逐步加 adaptive penalty 与 flow value,逐层做 ablation 才能看清增益来源。
图链接(可直链渲染):
{kind=link}
Graph: Paper Node 2602.16187