Title: World Guidance: World Modeling in Condition Space for Action Generation Authors: Yue Su, Sijin Chen, Haixin Shi, Mingyu Liu, et al. arXiv: https://arxiv.org/abs/2602.22010
Figure (HTML直链): https://arxiv.org/html/2602.22010v1/x2.png
{kind=link}
Problem framing
现有把“未来观测建模”接入 VLA 的方法,常在两端摇摆:要么表征太粗导致动作指导力不足,要么未来表示太重导致训练/推理成本上升。该文核心问题是:如何在可预测紧凑表示与动作可控细粒度信息之间取得可扩展平衡。
Core method
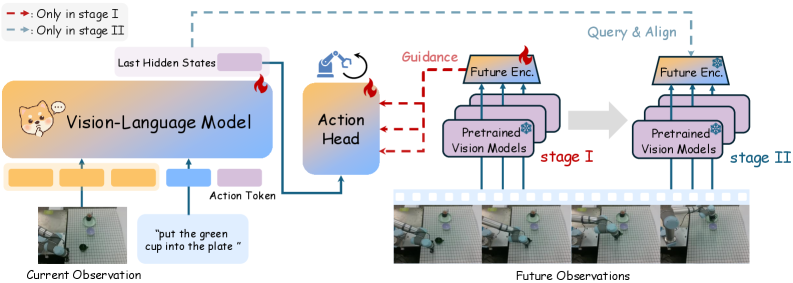
提出 WoG(World Guidance):先把未来观测映射到条件空间(condition space)形成可控中间变量,再由策略在该条件引导下生成动作。相比直接像素级未来预测,condition-space world modeling 更轻、更稳定,也更容易与动作头对齐。
Key equations and mechanisms
可写成两阶段目标: 其中 为语言条件, 为未来条件表示。训练上联合最小化未来条件预测误差与动作监督损失: 机制要点是用“条件空间一致性”代替高成本像素重建。
Experiment reading guide
- 先看相对主流 VLA baseline 的任务成功率增益。
- 再看长时任务与分布外场景(遮挡/扰动)是否仍有提升。
- 最后看 ablation:去掉 world guidance 后退化幅度是否显著。
Limitations
- 条件空间是否足够表达接触细节,仍依赖数据覆盖。
- 若未来预测偏差累积,仍可能把策略引向错误动作子空间。
Future work
- 与测试时纠偏(test-time adaptation)结合,形成闭环自修正。
- 引入显式接触/力学先验,提升接触丰富任务稳定性。
Replication angle
- 先复现 condition encoder + action head 最小系统。
- 重点扫两个超参:condition维度与预测步长。
- 记录端到端延迟与长时误差漂移,评估真实部署价值。
Graph: Paper Node 2602.22010